부스트캠프 AI Tech 2기 Day - 13,14 - model
-
model.save()
-
학습의 결과를 저장하기 위한 함수
-
모델의 형태(architecture)와 파라미터를 저장
-
모델 학습 중간 과정의 저장을 통해 최선의 결과모델을 선택
-
만들어진 모델을 외부 연구자와 공유하여 학습 재연성 향상
#print model's state_dict
print("Model's state_dict:")
for param_tensor in model.state_dict():
print(param_tensor, "\t", model.state_dict()[param_tensor].size())
torch.save(model.state_dict(),
os.path.join(MODEL_PATH, 'model.pt'))
new_model = TheModelClass()
new_model.load_state_dict(torch.load(os.path.join(
MODEL_PATH, "model.pt")))
torch.save(model, os.path.join(MODEL_PATH, 'model.pt'))
model = torch.load(os.path.join(MODEL_PATH, 'model.pt'))
Transfer learning
-
다른 데이터셋으로 만든 모델을 현재 데이터에 적용
-
일반적으로 대용량 데이터셋으로 만들어진 모델의 성능 높음
-
현재의 DL에서는 가장 일반적인 학습 기법
-
backbone architecture가 잘 학습된 모델에서 일부분만 변경하여 학습을 수행함
Freezing

Transfer learning
vgg = models.vgg16(pretrained=True).to(device) # vgg 16 모델을 vgg에 할당하기
class MyNewNet(nn.Module):
def __init__(self):
super(MyNewNet, self).__init__()
self.vgg19 = model.vgg19(pretrained=True)
self.linear_layers == nn.Linear(1000,1) # ahepfdp akwlakr Linear Layer 추가
# Defining the forward pass
def forward(self, x):
x = self.vgg19(x)
return self.linear_layers(x)
for param in my_model.parameters():
param.requires_grad = False # 마지막 레이어를 제외하고 frozen
for param in my_model.linear_layers.parameters():
param.requires_grad = True
Multi-GPU 학습

개념정리
-
Single vs Multi
-
GPU vs Node
-
Single Node Single GPU
-
Single Node Multi GPU
-
Multi Node Multi GPU
Model parallel
-
다중 GPU에 학습을 분산하는 두가지 방법
-
모델을 나누기 / 데이터를 나누기
-
모델을 나누는 것은 생각보다 예전부터 썼음 (AlexNet)
-
모델의 병목, 파이프라인의 어려움 등으로 인해 모델 병렬화는 고난이도 과제

class ModelParallelResNet50(ResNet):
def __init__(self, *args, **kwargs):
super(MOdel ParallelResNet50,self).__init__(
Bottleneck,[3,4,6,3], num_classes = num_classes, *args, **kwargs)
self.seq1 = nn.Sequential(
self.conv1, self.bn1, self.relu, self.maxpool, self.layer1, self.layer2).to('cuda:0')
self.seq2 = nn.Sequential(
self.layer3,self.layer4,self.avgpool,
).to('cuda:1')
self.fc.to('cuda:1')
def forward(self,x):
x = self.seq2(self.seq1(x).to('cuda:1'))
return self.fc(x.view(x.size(0),-1))
Data parallel

-
PyTorch 에서는 아래 두가지 방식을 제공 Data Parallel, DistributedDataParallel
-
Data Parallel - 단순히 데이터를 분배한 후 평균을 취함 -> GPU 사용 불균형 문제 발생, Batch 사이즈 감소 (한 GPU가 병목), GIL
-
DistributedDataParallel - 각 CPU마다 process 생성하여 개별 GPU에 할당 -> 기본적으로 DataParallel로 하나 개별적으로 연산의 평균을 냄
Data parallel
parallel_model = torch.nn.DataParallel(model) #Encapsulate the model
predictions = parallel_model(inputs) # Forward pass on multi-GPUs
loss = loss_function(predictions, labels)
loss.mean().backward()
optimizer.step()
predictions = parallel_model(inputs)
Distributed Data Parallel
train_sample = torch.utils.data.distributed.DistributedSampler(train_data)
shuffle = False
pin_memory = True
trainloader = torch.utils.data.DataLoader(train_data, batch_size=20, shuflle=False, pin_memory = pin_memory, num_workers=3, shuffle=shuffle, sampler = train_sampler))
def main():
n_gpus = torch.cuda.device_count()
torch.multiprecessing.spawn(main_worker, nprocs=n_gpus, args=(n_gpus,))
def main_worker(gpu, n_gpus):
image_size = 224
batch_size = 512
num_worker = 8
epochs = ...
batch_size = int(batch_size / n_gpus)
num_worker = int(num_worker / n_gpus)
torch. distributed.init_process_group(
backend='nccl', init_method = 'tcp://127.0.0.1:2568', world_size=n_gpus, rank=gpu)
model = MODEL
torch.cuda.set_device(gpu)
model = model.cuda(gpu)
model = trch.nn.parallel.DistributedDataParallel(model, device_ids=[gpu])
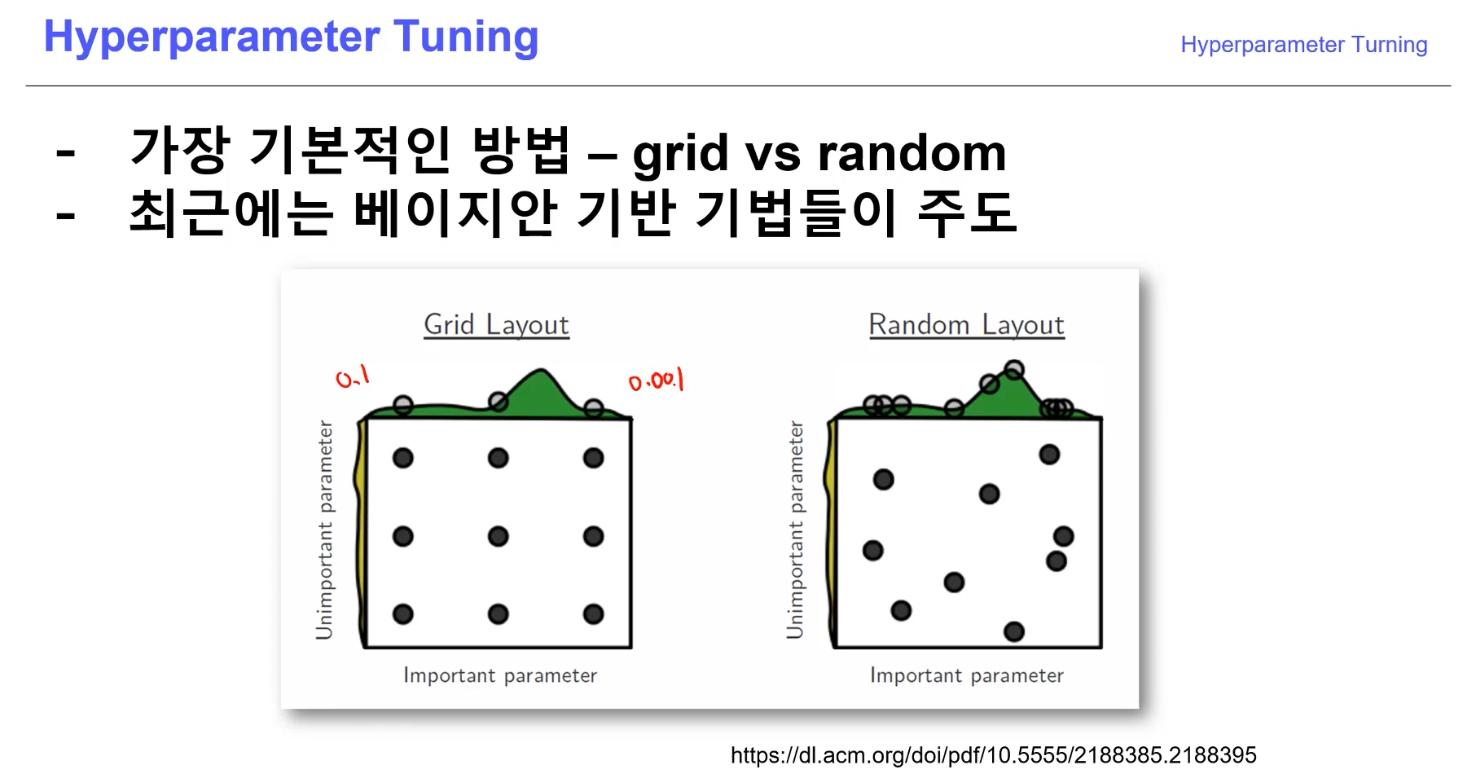
Hyperparameter Tunning
-
모델 스스로 학습하지 않은 값은 사람이 지정 (learning rate, 모델의 크기, optimizer 등)
-
하이퍼 파라미터에 의해서 값이 크게 좌우 될때도 있음(요즘은 그닥?)
-
마지막 0.01을 쥐어짜야 할 때 도전해볼만!
Ray
-
multi-node multi precessing 지원 모듈
-
ML/DL의 병렬 처리를 위해 개발된 모듈
-
기본적으로 현재의 분산병렬 ML/DL 모듈의 표준
-
Hyperparameter Search를 위한 다양한 모듈 제공

PyTroch Troubleshooting
OOM이 해결하기 어려운 이유들
-
왜 발생했는지 알기 어려움
-
어디서 발생했는지 알기 어려움
-
Error backtracking 이 이상한데로 감
-
메모리의 이전상황의 파악이 어려움
GPUUtil 사용하기
-
nvidia-smi 처럼 GPU의 상태를 보여주는 모듈
-
Colab은 환경에서 GPU상태 보여주기 편함
-
iter마다 메모리가 늘어나는지 확인!!

torch.cuda.empty_cache() 써보기
-
사용되지 않은 GPU상 cache를 정리
-
가용 메모리를 확보
-
del 과는 구분이 필요
-
reset 대신 쓰기 좋은 함수

tarinning loop에 tensor로 축적되는 변수는 확인할 것
-
tensor로 처리된 변수는 GPU 상에 메모리 사용
-
해당 변수 loop 안에 연산에 있을때 GPU에 computational graph를 생성(메모리 잠식)
total_loss = 0
for i in range(10000):
optimizer.zero_grad()
output = model(input)
loss = criterion(output)
loss.backward()
optimizer.step()
total_loss += loss

del 명령어를 적절히 사용하기
-
필요가 없어진 변수는 적절한 삭제가 필요함
-
python의 메모리 배치 특성상 loop이 끝나도 메모리를 차지함
for x in range(10):
i = x
print(i) # is printed
for i in range(5):
intermediate = f(input[i])
result += g(intermediate)
output = h(result)
return output
가능 batch 사이즈 실험해보기
- 학습시 OOM이 발생했다면 batch 사이즈를 1로 해서 실험해보기
oom = False
try:
run_model(batch_size)
except RuntimeError:
oom = True
if oom:
for _ in range(batch_size):
run_model(1)
torch.no_grad() 사용하기
-
Inference 시점에서는 torch.no_grad() 구문을 사용
-
backward pass 으로 인해 쌓이는 메모리에서 자유로움
with torch.no_grad():
for data, target in test_loader:
output = network(data)
test_loss += F.nll_loss(output, target, size_average=False).item()
pred = output.data.max(1, keepdim=True)[1]
correct += pred.eq(target.data.view_as(pred)).sum()
예상치 못한 에러 메세지
-
OOM 말고도 유사한 에러들이 발생
-
CUDNN_STATUS_NOT_INIT 이나 device-side-assert 등
-
해당 에러도 cuda와 관련하여 OOM의 일종으로 생각될 수 있으며, 적절한 코드 처리의 필요함
그 외..
-
colab에서 너무 큰 사이즈는 실행하지 말 것 (linear, CNN, LSTM)
-
CNN의 대부분의 에러는 크기가 안맞아서 생기는 경우 (torchsummary 등으로 사이즈를 맞출 것)
-
tensor의 float precision을 16bit로 줄일 수도 있음